张子墨
Sunmiss · 2004 · AI 产品经理
AI 产品经理 · LLM 产品化
数据驱动决策者——不凭空猜测用户需求,用数据和实测说话
3 个 AI 产品从 0 到 1 · 每个都经历「需求→方案→选型→落地→验证」全流程闭环
用户洞察· 数据驱动· 系统设计· AI 产品化
Sunmiss · 2004 · AI 产品经理
AI 产品经理 · LLM 产品化
数据驱动决策者——不凭空猜测用户需求,用数据和实测说话
3 个 AI 产品从 0 到 1 · 每个都经历「需求→方案→选型→落地→验证」全流程闭环
用户洞察· 数据驱动· 系统设计· AI 产品化
先定义目标体验再反推方案,通过用户行为数据(选取率、留存节点、功能渗透率)找到真问题,而非凭直觉做决策
大数据专业训练 + 实践:从埋点设计到指标定义到统计验证,能将模糊的"用户反馈"转化为可衡量的产品指标
擅长将复杂规则拆解为可配置的模块化系统,降低迭代成本。每个项目都做到"调参不改代码",让非技术角色也能参与迭代
将 LLM、RAG、Agent、Multi-Agent 等 AI 能力落地为可交付的产品功能。理解 AI 能力边界(幻觉控制、Prompt 稳定性、上下文窗口限制),在模型能力与用户体验之间做务实取舍
用户分层 × 情感引擎 × RAG 记忆 · 让 AI 角色真正"活"起来
一款 AI 驱动的动漫角色互动游戏,用户可与 AI 角色进行自然对话并建立情感关系。核心挑战是在「AI 生成内容的不可控性」与「对话自然度」之间找到平衡——既不能让角色人设崩塌,也不能让对话像模板一样机械。
18 — 28 岁 ACGN / 二次元文化爱好者,以学生和年轻职场人为主。对动漫角色有情感投射,希望通过与 AI 角色互动获得陪伴感和情感满足。游戏经验丰富,对交互流畅度敏感;对角色"人设一致性"有高要求——能接受角色性格鲜明,但无法容忍角色"说错话"或"OOC(Out of Character)"。
现有 AI 聊天产品普遍"说啥都像 AI",缺乏角色个性和语言风格的一致性。用户反馈:"我知道它是 AI,但至少让它说话像这个角色。"
对话超过一定轮次后,AI 完全忘记之前聊过什么。用户昨天分享过的事,今天就要重新解释——"这根本不是朋友,是金鱼。"
无论用户说什么,AI 都回以相似的积极态度。用户无法感知到"关系在变化"——没有亲近感加深的过程,也没有闹别扭后的和解,情绪体验扁平。
角色"说话像这个角色",不出现人设崩塌。这是用户在首次体验 5 分钟内形成的判断——过了就留,过不了就走。
角色能记住关键对话,用户不需要反复解释。"上次我跟你说的那个考试,我过了"——角色应该能接上这个上下文。
角色能感知用户情绪状态并调整反馈方式。用户沮丧时给安慰,开心时一起兴奋——而非永远"你好棒"的模板回应。
用户感觉这个角色是"活的"——有成长、有变化、有关系深度。这是用户愿意长期留存并主动推荐的核心驱动力。
三种模式覆盖不同投入意愿——陌生人模式降低首次使用门槛;成长模式以亲密度驱动关系进化;陪伴者模式跳过数值系统直接进入亲密对话。分层依据来自用户行为分析,而非凭直觉划分。
-100→+100 亲密度模型 × 10 级关系阶段,采用不对称波动(正向+1/负向-2)模拟真实人际关系权重。4 维情绪状态作为系数调节亲密度变化速率,本质是「用户状态 × 内容策略」的推荐系统。
用 LanceDB 向量数据库存储角色设定和历史对话,Function Calling 按需检索相关上下文——避免了 Prompt 过长导致的注意力稀释,又保证角色记忆的连续性。
角色设定通过 Function Calling 结构化注入,限定 LLM 在预定义的角色人格、知识边界和剧情框架内生成内容,超出设定的话题自动拦截。输出层增加敏感词过滤与格式校验。
SSE 流式透传实现打字机效果,用户感知响应延迟 < 500ms。支持对话中断与重新生成,提升交互可控感。
-100→+100 亲密度 × 10 级关系阶段,4 维情绪(愉悦/悲伤/愤怒/平静)作为系数调节亲密度变化。同一对话在不同情绪状态下产生差异化反馈。
LanceDB + DashScope Embedding 将角色设定和历史对话向量化。Function Calling 按相关性阈值(0.75)决定是否检索,降低无关上下文注入。
LLM 根据亲密度阶段动态生成剧情场景。MiniMax API 辅助场景画面生成,形成「记忆检索→场景生成→行为约束」的内容供给闭环。
Prompt 详细度反复 A/B 测试——太详细对话僵硬,太精简人设崩塌。最终选定精简 Prompt + Function Calling 动态注入方案,在自然度与稳定性之间找到最优解。
当前对话历史仅存浏览器内存,刷新即丢失。后续版本将引入服务端持久化,支持跨会话记忆连续性。
目标:避免 Prompt 过长导致 LLM 注意力稀释
传统 RAG 做法是将所有相关记忆拼接进 Prompt,但对话轮次增加后 Prompt 膨胀严重。Function Calling 让模型「按需索取」——需要回忆时主动调用检索函数,不需要时保持 Prompt 精简。实测将 Prompt token 消耗降低约 40%,且角色人设一致性反而提升。
目标:让关系发展有真实人际关系的「张力」
真实人际关系中,一次争吵的伤害远大于一次赞美的温暖——负面事件的心理权重天然更高。正向+1/负向-2 的不对称设计让玩家更谨慎对待对话选择,避免了「随便点点也能满好感」的敷衍感,提升了情感投入度。
目标:确保 7×24 对话服务不中断
对话产品对延迟和可用性极其敏感——用户说了话等不到回复的体验是不可接受的。配置 DeepSeek 主 API + 备用 LLM 双通道,超时/限流自动切换,用户侧无感知。切换时上下文完整保留,不会出现「AI 突然失忆」的情况。
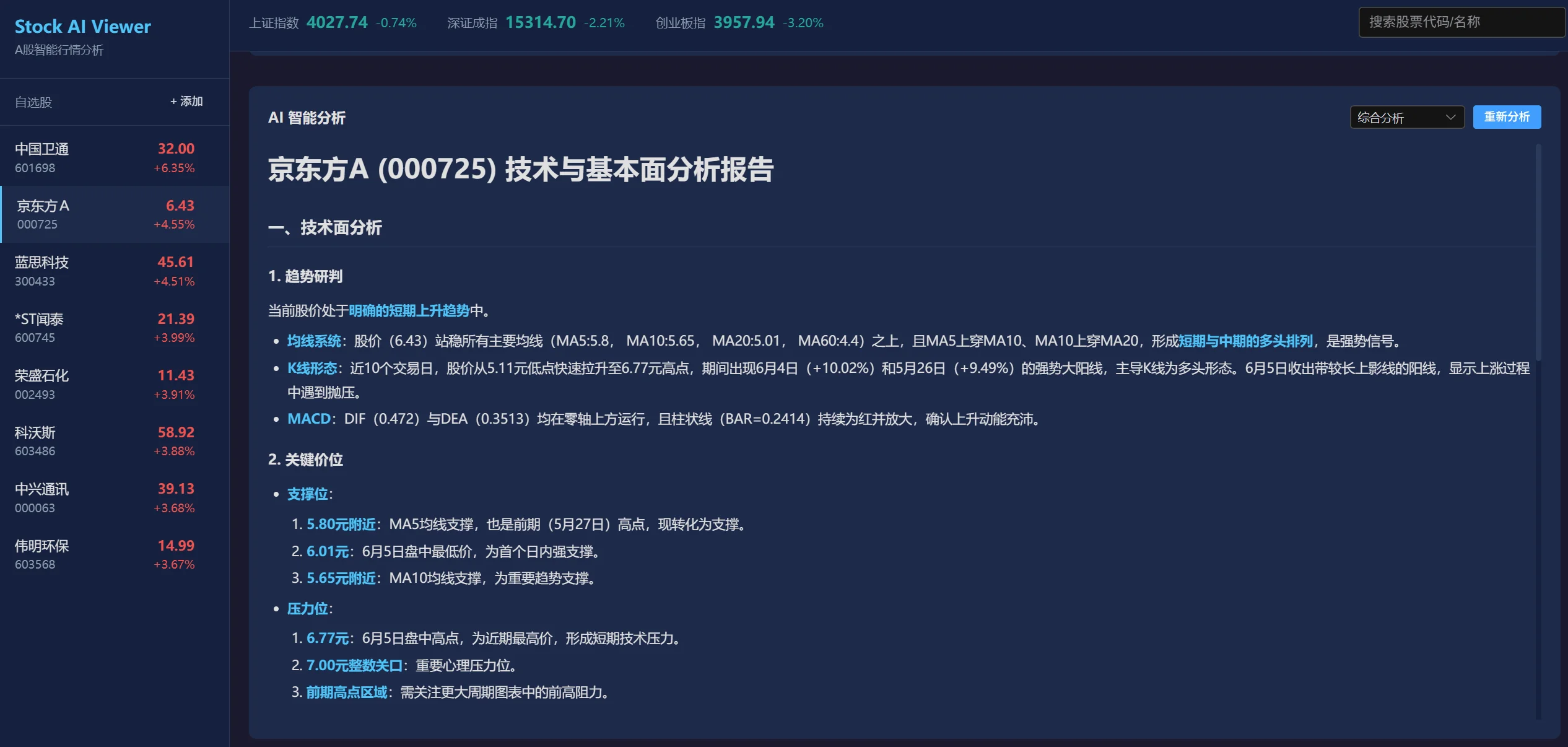
 角色对话 · 亲密度与情绪实时反馈
角色对话 · 亲密度与情绪实时反馈
 角色选择 · 三种模式覆盖不同投入意愿
角色选择 · 三种模式覆盖不同投入意愿
 动态场景生成 · LLM 根据亲密度阶段生成剧情
动态场景生成 · LLM 根据亲密度阶段生成剧情
 角色管理后台 · 调参不改代码的配置系统
角色管理后台 · 调参不改代码的配置系统
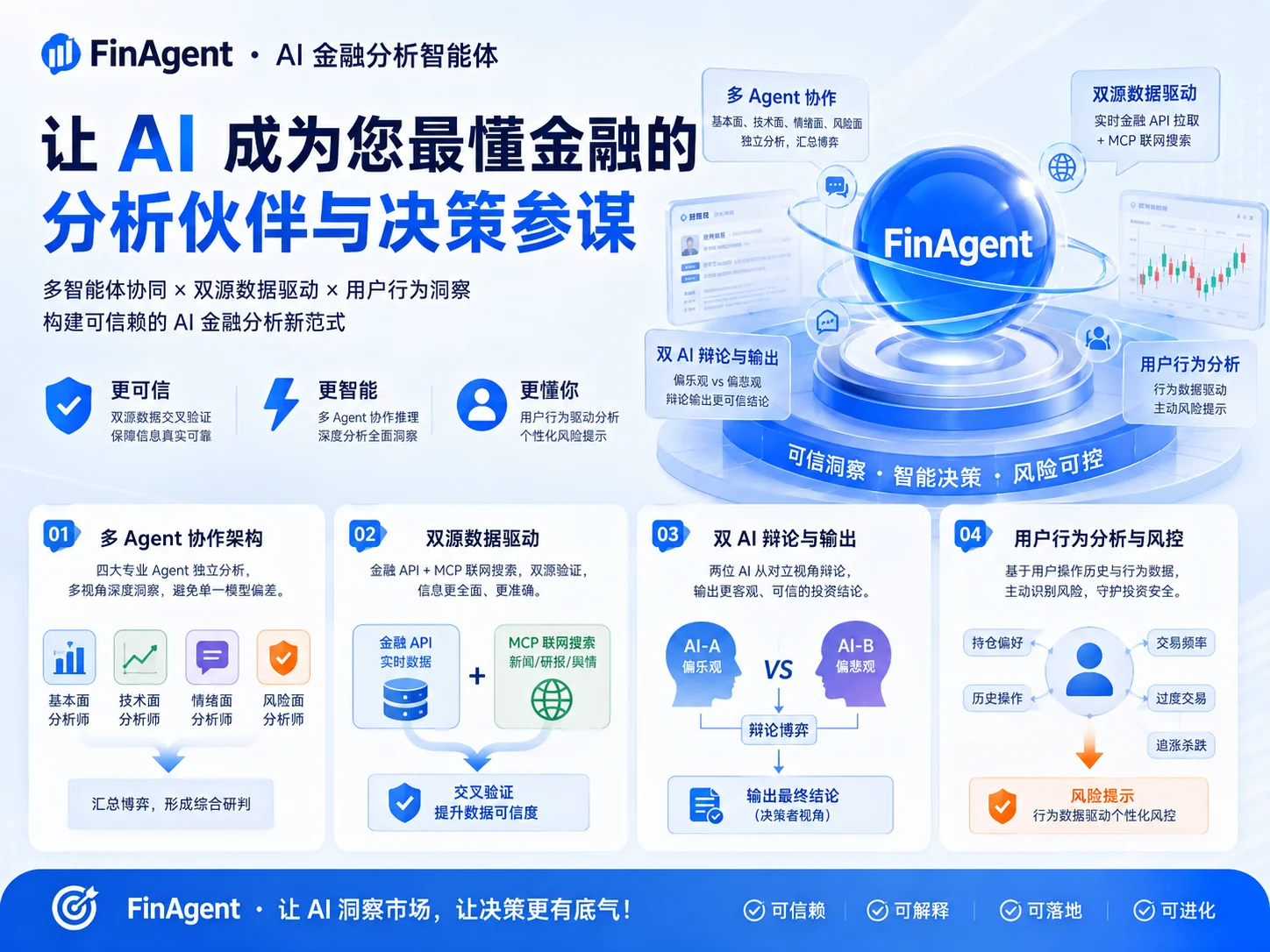
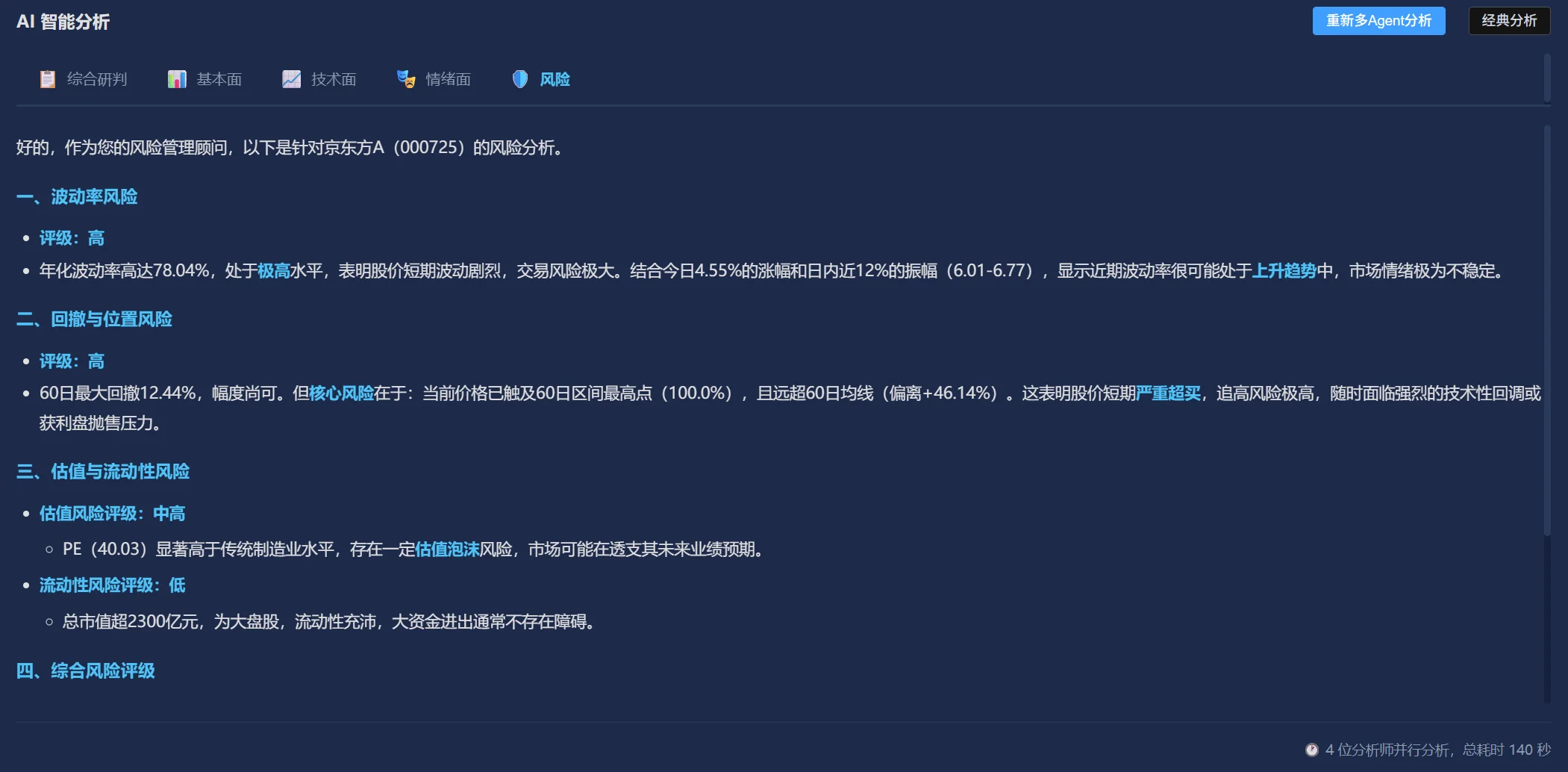
4 Agent 协作 × 双源数据 × 双 AI 辩论 · AI 做参谋,用户做决策
一款 AI 驱动的金融分析工具,通过 Multi-Agent 协作架构从多角度分析股票。核心挑战是 AI 金融产品信任门槛极高——如何在「AI 建议」与「用户自主决策」之间建立可信赖的协作关系?产品定位:AI 是参谋团,不是决策者。
25 — 40 岁个人投资者(散户),有一定的股票投资经验和基础金融知识,但非专业分析师。工作忙碌,每天只有碎片时间关注市场。核心矛盾:既不相信AI能替自己做决策,又需要AI帮忙处理海量信息。对AI金融产品的信任门槛极高——"你说得对但我不信你"是常态。
财报、新闻、技术指标、社交媒体舆情……信息太多太杂,散户没有精力做系统整理。最终"凭感觉买",缺乏理性决策依据。
看了几篇分析文章就形成先入为主的判断,忽视反面信息。没有"反对派"来挑战自己的观点——这是散户追涨杀跌背后的认知根源。
市面上AI选股工具直接输出"买入/卖出"建议,用户看不到推理链条。在金融这种真金白银的领域,"黑盒建议"无法建立信任——你敢跟着一个不解释为什么的建议操作吗?
"帮我整合信息,别让我自己翻几十个网页。"——用户需要的是高效的信息聚合工具,一个入口看全貌。
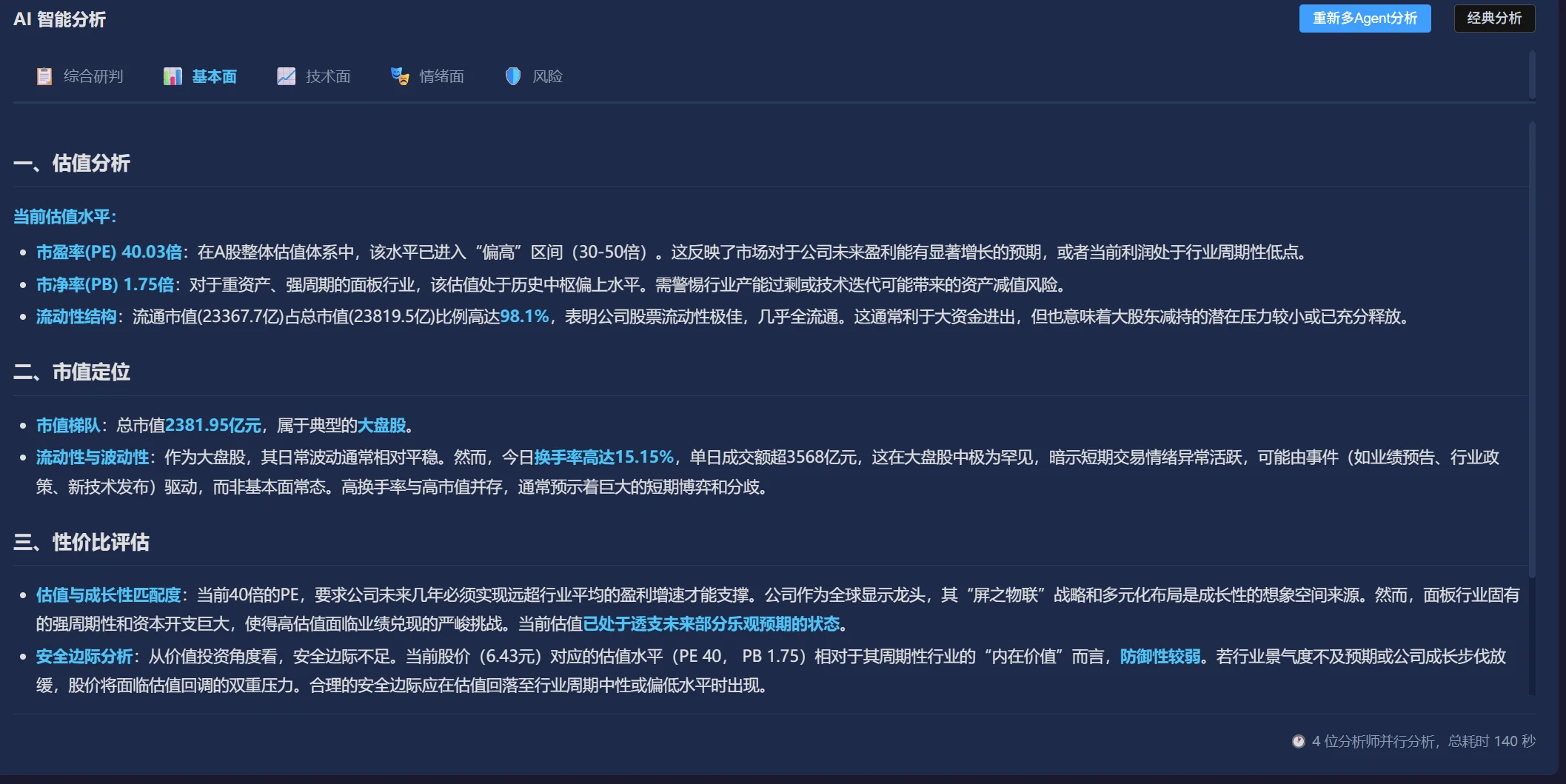
从基本面、技术面、情绪面不同视角给出分析,让用户看到完整的图景——而非单一维度的片面结论。
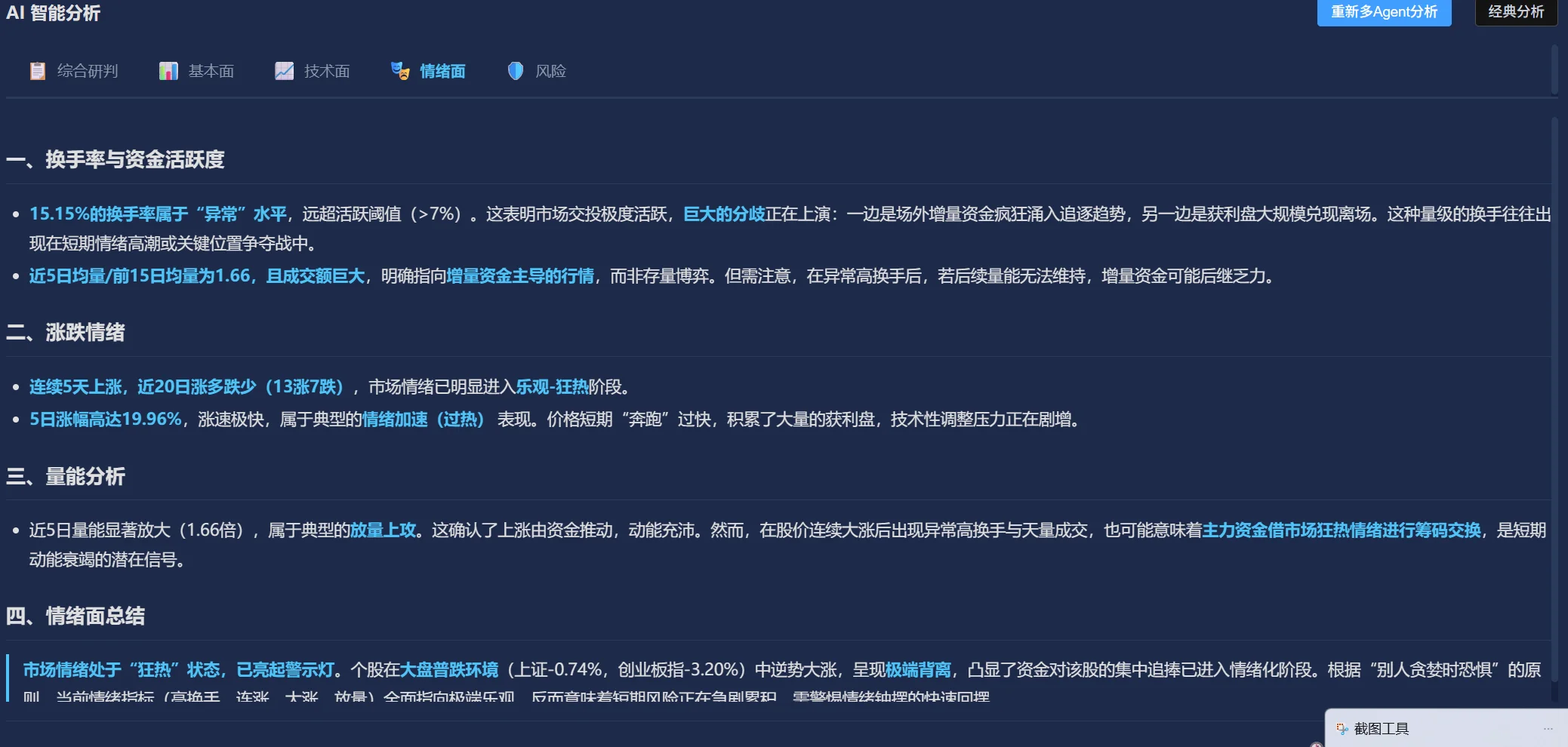
在用户冲动交易时主动提醒,识别追涨杀跌等情绪化操作模式。"参谋的责任不只是提供信息,还要在将军犯错时拉一把。"
用户把 AI 当作"可以质疑、可以追问、可以对比"的分析伙伴。决策权始终在用户手里,但 AI 提供了足够透明的推理过程,让用户有信心按下"确认"键。
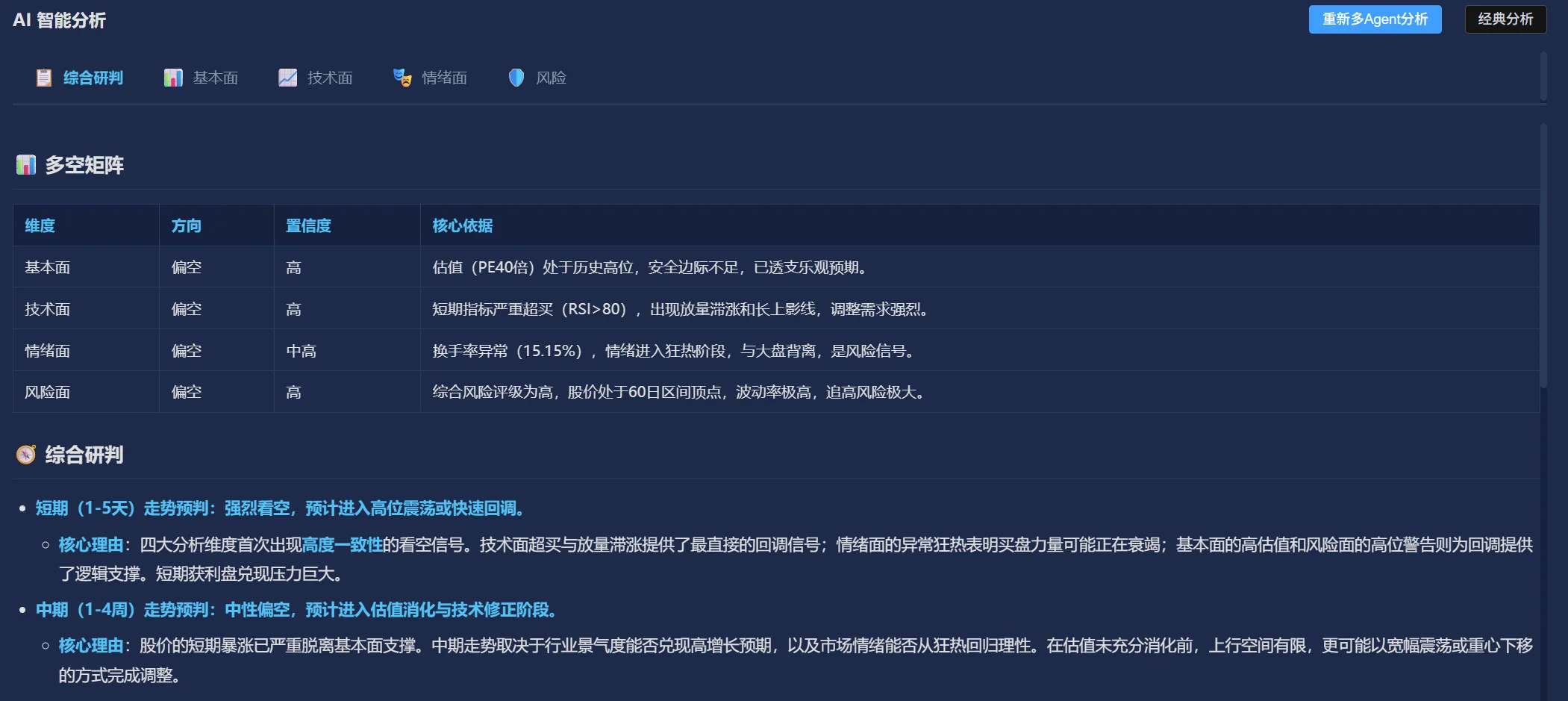
基本面/技术面/情绪面/风险四 Agent 独立分析后汇总博弈,而非单一模型「一言堂」——模拟真实投资团队的多元视角交叉验证。
实时金融 API 拉取行情/财报/新闻等结构化数据 + MCP 协议联网搜索获取全网最新资讯——两者互补,保证数据精度又覆盖信息广度,避免模型训练截止日期带来的信息盲区。
两个 AI 对同一股票多空辩论(一个偏乐观、一个偏悲观),用户看到完整推理过程而非结论——核心产品决策:将 AI 定位为「参谋团」而非「决策者」,降低盲目信任风险。
基于用户操作历史、持仓偏好、交易频率等行为数据,AI 分析用户性格倾向(过度交易、追涨杀跌、过度保守),在关键操作节点主动进行风险提示。
财报解读、估值分析、行业对比。从财务数据中提取关键指标变化趋势,生成结构化分析报告。
K 线形态识别、技术指标分析(MACD/RSI/布林带)、支撑阻力位判断。AI 用自然语言解读技术信号含义。
市场舆情分析,通过金融 API 新闻 + MCP 联网搜索获取最新资讯,判断市场情绪偏向(乐观/悲观/中性)。
持仓风险评估、操作风险提示、止损建议。结合用户行为数据做个性化风控,拦截冲动交易。
金融 API 提供结构化精度,MCP 搜索覆盖信息广度。两者互补避免了单一数据源的盲区——API 保证数据准确性,MCP 保证时效性。
双 AI 辩论增加了可信度但拉长了分析时间。后续版本将引入辩论轮次控制(默认 2 轮),用户可按需展开深度辩论。
目标:避免单一模型的系统性偏见
单模型分析存在两个致命问题:(1) 模型训练数据的时间偏差导致分析滞后;(2) 单一视角无法自我纠错。四 Agent 各自独立获取数据、独立分析、汇总博弈,若两 Agent 结论相反则触发双 AI 辩论——本质是将「模型的不确定性」转化为「用户可感知的多元视角」。
目标:在 AI 能力与用户信任之间划定清晰边界
金融领域的决策后果是真实的金钱损失。将 AI 定位为参谋团而非决策者,有三个产品层面的考量:(1) 降低用户对 AI 的盲目信任——看到辩论过程自然产生审慎态度;(2) 保留用户的控制感和最终决策权;(3) 合规层面——不构成投资建议,降低产品风险。
目标:金融数据不允许 AI 自由发挥
三层防线:(1) 数据溯源——所有 LLM 输出的数据结论必须可追溯到具体 API 字段或新闻链接;(2) 格式校验——数值范围检查、逻辑一致性校验,拦截明显的数据矛盾;(3) 无法溯源的推断性内容强制标注「仅供参考」。双 AI 辩论本身也是对抗手段——两个对立视角互相校验,降低单模型「自信编造」的概率。

简历 × 面试 × 规划 · 覆盖求职三阶段的 AI 职业助手
一款覆盖求职全链路的 AI 职业规划工具——从简历优化、模拟面试到职业路径规划。核心挑战:求职是低频高决策成本场景,如何让 AI 在「标准化建议」和「个性化指导」之间找到平衡,让用户真正感受到「被理解」而非「收到模板」?
20 — 28 岁应届毕业生及 1-3 年职场新人,正在主动找工作或考虑职业转型。对 ATS(Applicant Tracking System)筛选机制不了解——"投了 50 份简历都没回应,不知道问题出在哪"。面试经验不足,面对高压面试场景容易紧张。核心矛盾:需要AI帮忙但又怕"造假"——希望简历被优化,但不希望失去真实性。
海投简历杳无音信,不知道为什么被筛掉。核心问题往往不是"不够优秀",而是"不会说ATS能听懂的话"——关键词密度、格式兼容性、经历描述结构任何一个环节都可能被机器误杀。
面经看了不少,但一上阵就紧张。没有安全的试错环境来练习——朋友没空陪练,辅导班太贵。核心需求是"低压力、高反馈"的模拟环境。
"我不知道自己适合做什么"——这是校招季最高频的用户困惑。缺乏系统性的自我认知和行业信息,面对海量岗位无从下手,决策高度依赖偶然性和身边人建议。
"我的简历能被机器读到。"用户的第一道坎是被看到——在优化内容之前,先要保证简历不会因为格式或关键词问题被自动筛掉。
简历不只是"被看到",还要"打动 HR"。AI 帮助用专业语言重新表达真实经历,让每段经历都体现可衡量的价值——而非简单堆砌关键词。
通过多角色模拟面试发现自己的薄弱环节——技术深度够不够?表达清不清晰?气场稳不稳?每次模拟都有具体反馈,知道"下一次面试我该改进什么"。
有一个基于自身背景和行业数据的职业发展规划,知道"我适合什么方向、需要补什么技能、下一步该做什么"——从被动海投变为主动选择。
模板推荐(行业/岗位智能匹配)→ AI 内容修改(语义级重写,非简单关键词替换)→ 一键导出 PDF(排版引擎保证格式一致性),覆盖求职准备全链路。
AI 扮演技术面试官/业务负责人 + HR 双角色交叉评估——从「专业能力」和「文化匹配」两个维度模拟真实招聘筛选逻辑,而非单一视角打分。
针对企业 ATS 系统简历初筛逻辑,分析关键词密度、格式兼容性、经历描述结构——核心洞察:不是教用户「造假」,而是帮用户「不被机器误杀」。
基于用户背景、技能树、目标岗位生成个性化职业路径(短期/中期/长期),包含行业趋势分析、技能缺口识别、学习路径推荐,覆盖从「定位」到「成长」的完整决策链路。
AI 深度解析简历内容,识别技能、经历、项目等维度。语义级分析而非关键词匹配,理解经历背后的能力而非表面文字。
技术面试官评估专业深度,HR 评估文化匹配与软技能。双角色独立打分后交叉对比,输出综合评估报告。
短期(1年技能提升)→ 中期(3年岗位进阶)→ 长期(5年职业方向)三层规划。包含行业趋势数据 + 技能缺口分析 + 学习路径推荐。
服务端渲染 + 客户端渲染双保险,保证排版格式一致性。支持多模板切换,一键导出 A4 标准简历。
简历修改类操作采用三步流程,用户始终有最终审核权。这解决了 AI 建议被盲目接受的风险,同时保持了 AI 的高效辅助价值。
当前仅技术面试官 + HR 双角色,后续将增加更多行业角色(如产品总监、CTO),覆盖更多求职场景。
目标:在 AI 效率与用户控制权之间找平衡
直接改写虽然高效但有两个问题:(1) 用户失去对简历的控制感——这是求职者最在意的个人文档;(2) AI 可能误解用户的真实意图。三步流程让 AI 提供建议但用户做最终决策,既保留了 AI 的效率优势,又保护了用户的代理感。
目标:建立产品信任,避免「优化」变质为「作弊」
ATS 优化很容易滑向关键词堆砌和虚假经历。产品的核心洞察是:很多优秀候选人被机器误筛,不是因为不够格,而是不会「说机器能听懂的话」。帮用户用 ATS 友好的语言表达真实经历,本质是降低信息不对称,而非教人造假。
目标:避免「模板式」职业建议
三个层次实现:(1) 结构化 Prompt 模板限定输出格式但允许内容发散;(2) 关键结论(薪资范围、行业趋势数据)通过 MCP 联网检索最新信息做事实校验并标注来源与时效性;(3) 用户背景信息作为 Prompt 上下文注入,确保建议基于真实情况而非通用模板。API 层面配置主备双通道,保证长链路任务不中断。
大数据专业背景为 AI 产品经理工作提供了两个独特优势:
(1) 数据驱动决策——统计学训练让我习惯用数据验证假设,而非凭直觉做判断。从埋点设计到指标定义到统计验证,将模糊的「用户反馈」转化为可衡量的产品指标。
(2) AI 技术理解——专业课程体系让我能深入理解 LLM 的能力边界(幻觉、上下文窗口、Prompt 稳定性),在模型能力与用户体验之间做务实取舍。
在校期间独立完成 3 个 AI 产品从「需求→方案→AI 选型→落地→验证」全流程闭环。